作业一:计价 Skill¶
作业目标
利用 Claude Code 的 skill-creator 创建一个 LLM 计价查询 Skill。
完成后,你在 Claude Code 里输入 /llm-pricing,就能一句话查到主流大语言模型的实时调用价格。
作业提交¶
-
截止日期:2026年4月21日 23:59
-
提交: 邮件: mjay.lanlan2943914182[at]gmail.com
- 格式要求:zip文件,里面是一整个Skill文件夹
- 标题注明:"你的真实姓名-Agent实战-作业一"
核心意图¶
上一课,我们拆解了大模型的计价体系:五六家主流厂商、输入输出差别计价,甚至还有缓存命中的浮动机制。在真实的开发选型中,每次都要被迫翻阅各方官网拉表对比,过程枯燥且低效。
真正的问题在于将精力损耗在了记忆、检索重复性数据上。 翻阅长篇文档核对计费标准的行为,本质上完全可以交由自动化流程解决。
第一个实战作业的目标便在于此:把“手工查资料”沉淀为随手调用的系统级工具。你将体会到如何把日常零碎的、过度依赖经验的角落痛点抽离成可复用的技术资产。
基础要求¶
本作业的基础目标是实现一个功能完整的计价 Skill。
具体步骤:¶
- 寻找数据来源:可以通过 llmpricing.dev 或 openrouter.ai 等网站,确定你想让 Agent 如何获取最新价格。当然也可以手动整理好常用模型的价格表预置在 Skill 里,只是数据有过时的可能。
- 安装工具:如果在导论课没安装,先通过命令
npx skills add https://github.com/anthropics/skills --skill skill-creator引入技能创建器。 - 编写 Prompt 并创建:在 Claude Code 中唤起
/skill-creator,跟着它的交互逐步完成功能配置。💡 避坑提示:不要笼统地说“帮我查个价格”。明确地告诉它我们要查哪些字段:比如分别列出输入阶段(Input)和输出阶段(Output)的千兆 Token 价格,并且当用户查询时,固定套用 Markdown 表格形式做结构化输出。
- 反复调试:运行你编写的新技能,随便试几个模型。如果报错,或是输出乱码没对齐,不要气馁,直接向 Claude Code 反馈它的问题,让它帮忙对
.claude/skills下面的配置文件进行修改。
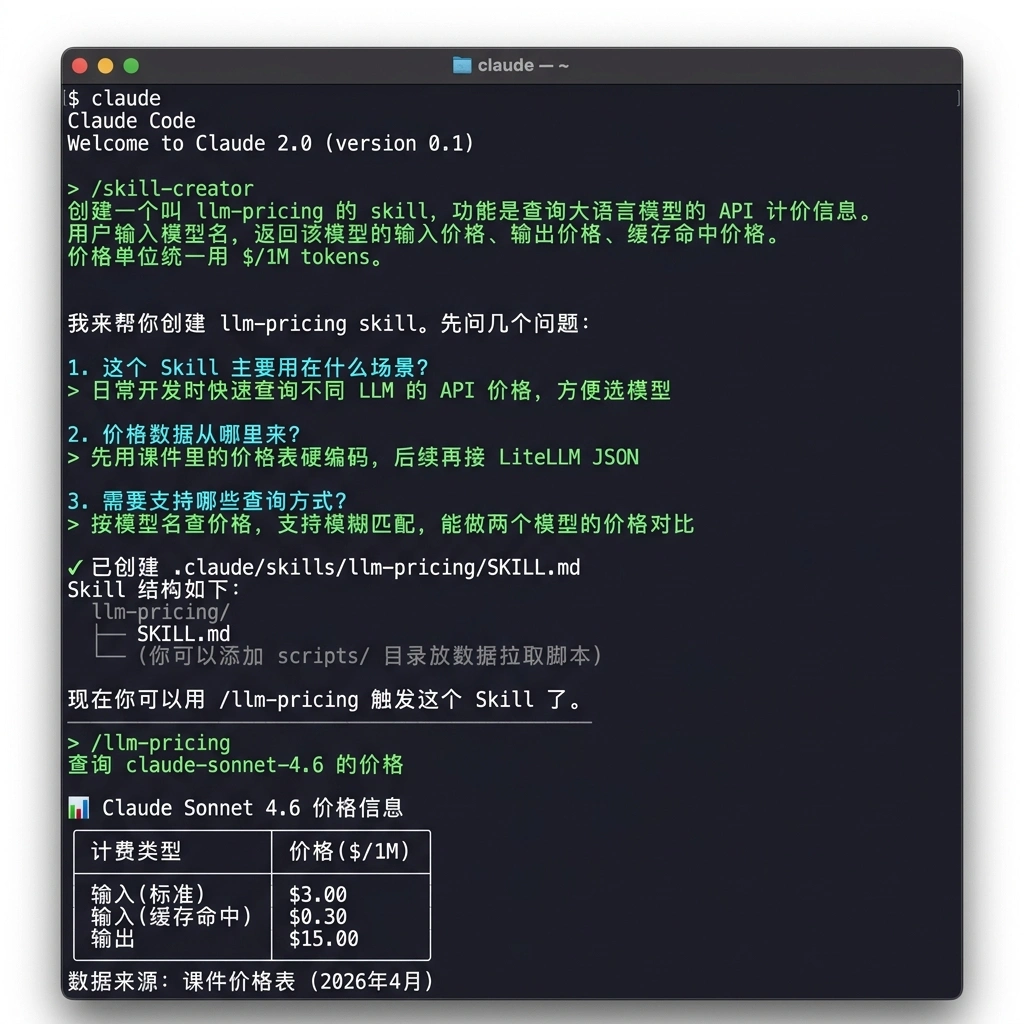
目标验证¶
当你的技能构建完毕,它需要满足下列基础验收条件:
- 可用性:触发 Skill 后,输入确切模型名称(如
claude-sonnet-4.6),即可得到精准的计费反馈。 - 覆盖率:内置数据或接口源需覆盖课件「主流模型价格对比」表格中的至少 5 项对比标的。
- 执行结果:回答没有冗长的铺垫,仅以你约定的信息格式直接输出。
进阶要求¶
在最基础的实现方案里,价格是通过硬编码直接写在配置表(Prompt)中的。这种方案存在致命缺陷:大模型价格随时间快速下调,硬编码数据无法自适应更新机制。
进阶实施的核心,是为主数据绑定能够从外界自动更新的渠道。你可以考虑以下两种主要方案的任何一种进行尝试:
方案 A:引入辅助脚本做本地缓存¶
在你的技能目录下利用模型自动编写拉取脚本(Python或是Bash皆可),直接对接 LiteLLM 数据体系,并定期覆写一份本地记录以便下一次调用。
提示
你不需要自己吭哧吭哧手写脚本,大模型会全部包揽。关键问题是在你的 Prompt 里指明逻辑依赖:存到哪里、拉什么字段以及何时查询。
方案 B:依赖底层工具穿透网络¶
在 SKILL.md 中直接命令 Claude Code 每次被唤起时,执行终端的 curl 或自带 Web 访问工具即时抓取对应的数据切片。这需要你在提示词里清晰地刻画数据提取坐标和 URL 连接。
挑战要求¶
这是对你掌控技术边界和理解工作流的拓展。基于该场景可以继续引申出以下几种变种工具,你可以挑选符合个人工作流的选项:
💰 综合成本测算¶
由单价查询提升至业务估算平台。设定实际情境输入量级即可看到每种选型背后的月度流水测算。
📊 引入上下文多维评估¶
不仅反馈每 1M Token 价格,一并带出上下文最大窗口值限制(Context Window)与参数维度,打造综合信息维度的对比。
🔍 联动 ccusage 查看自己的资金损耗¶
ccusage 作为能一键统计开发者 Claude Code 测试开销的标杆开源项目,如果能利用本次搭建的技能调用它查询出的总账和模型单价进行勾兑比对:你的模型消费、项目调用量即刻转化为极高内聚的终端面板反馈。
提交方式¶
将文件与运行结果提交为压缩包,完成结案:
- Skill 文件夹:将你的整个
.claude/skills/llm-pricing/产出目录打包为 zip 。(如果不熟悉命令行打包,可以在终端直接通过命令要求模型处理:帮我把 .claude/skills/llm-pricing 目录打包成 zip文件) - 使用截图:务必提交至少两张实际查询响应效果终端图示。
- 一句话说明:描述技能背后所使用的数据流源节点和特征(比如:硬编码还是脚本更新源)。
将打包完成的成果发至课程群,标注:【作业一】+ 你的名字。
别只是走个流程
我们帮你看作业的时候,重点关注你的 SKILL.md 指令约束。如果其中全是大模型套话、无数据源指向且无固定的结构控制,这依然代表只是走完了流程。运用 AI 编写工具是基本逻辑框架,而在哪些地方要设置阻流点做格式约束并提取,那才是你需要真正落地的工程判断。
常见问题¶
如果不懂编程能完成吗?
完全可以。基础要求剥离了脚本写作,你扮演的角色是系统架构师:使用人类语言设定触发场景与输入预设,核心构建和逻辑兜底交给内建的 creator 实现。
为什么获取外部庞大 JSON 容易出错或者失忆?
将阅读复杂体量文件的机械活交由工具端。如果你希望它分析复杂的外部大盘数据源,务必锁定提取字段。时刻记住你的定位是流程控制者,不要沉陷在底层数据的整理里。
为何触发时会有大量无用格式输出?
提示词控制存在空隙或盲区。常见问题是:没有事先声明数据载体格式表格、未能交代若匹配落空的失败回复对齐。Prompt 逻辑的严密决定了你拥有的是个玩具还是强力的助理工具。